Multi-Agent Analytics
vs-NLQ — Multi-Agent Intelligence Platform
E-commerce & fraud analytics — ask in plain English, get tables, charts, maps and exportable investigation reports.
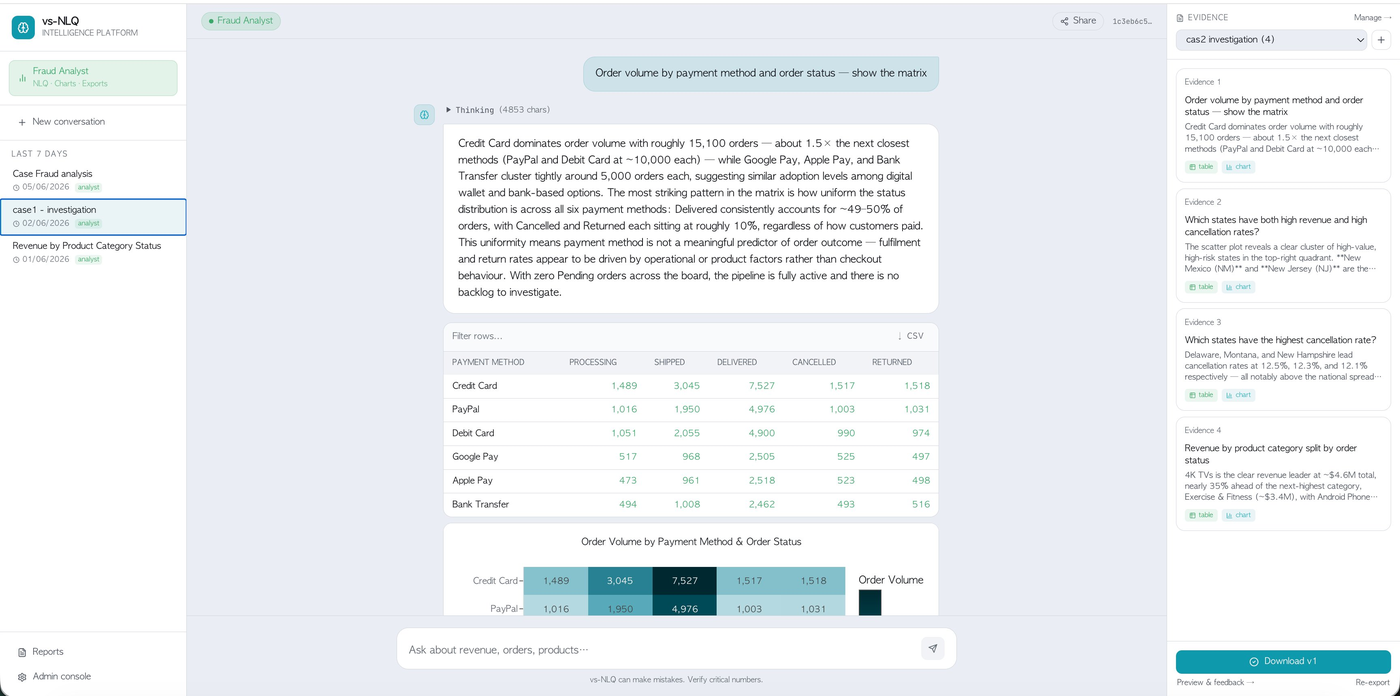
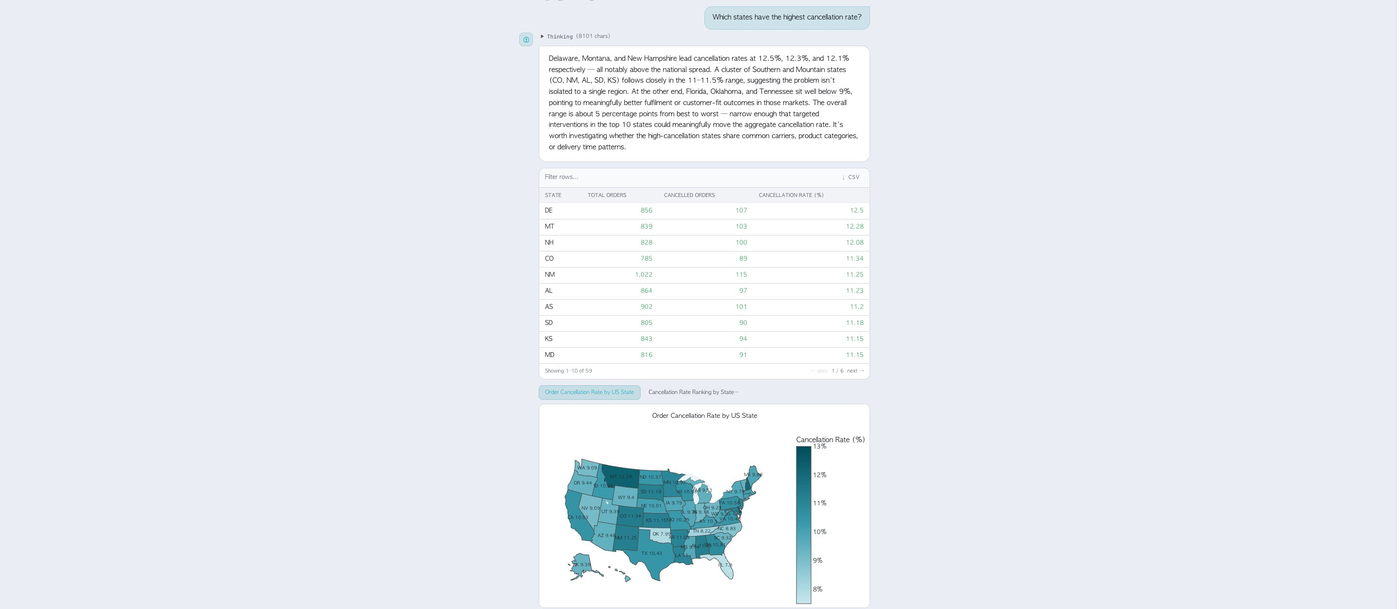
- Natural language → SQL & Cypher over real e-commerce data
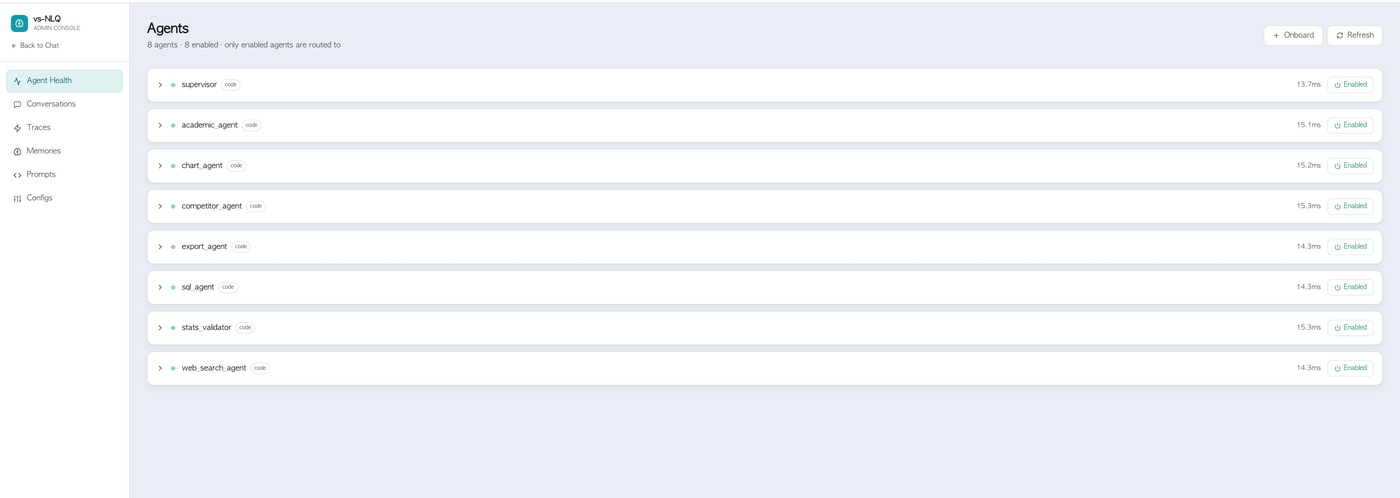
- Supervisor routing across 8 specialist agents — SQL, chart, stats validator, competitor, academic, web search and export
- Input / output / action guardrails with semantic & procedural memory
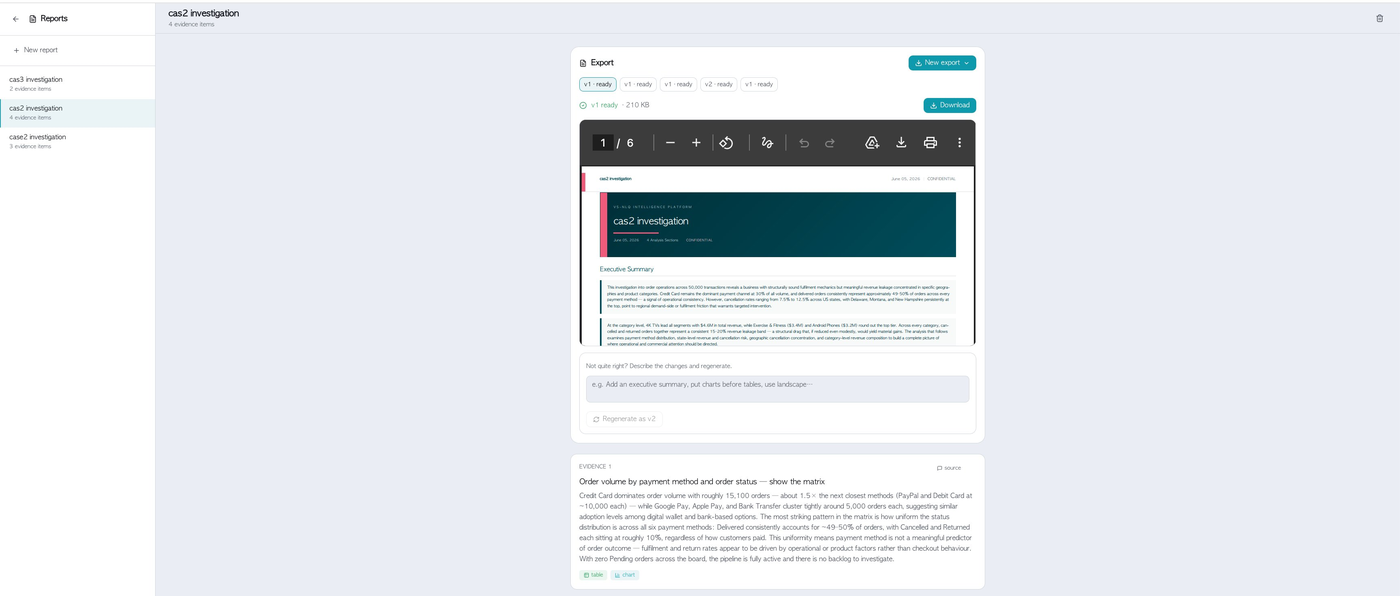
- Evidence collection → auto-generated, versioned PDF reports
- Full observability — traces, memories, prompts and agent health in an admin console
LangGraphAWS AgentCoreBedrockLangSmithRDS PostgreSQLDynamoDBNeo4jFastAPIReact